
http://dailycaller.com/2014/06/30/noaa-quietly-reinstates-july-1936-as-the-hottest-month-on-record/
These are the headlines today and the topic has blown up on the blogosphere lately, basically accusing NOAA of “cooking” the historical climate data. There is a simple explanation for what happened.
The graphs in the article and NOAA's "State of the Climate" reports are based on NOAA National Climatic Data Center's "Climate Division" data set.
The "Climate Division" data set divides each state into 6-10 climate divisions and then averages all daily temperature and precipitation observations in each climate division into areal and monthly averages. The benefits of using the climate division data rather than individual weather stations is that it is serially complete back to 1895 and you don't have to worry so much about biases and jumps in the individual stations measurements (from instrument changes, observation practices, station moves, etc.) or worry about stations having different recording periods or missing data.
This data set also compiles the monthly averages into State, Regional, and National averages.
Earlier this year NOAA recomputed the entire Climate Division, adding more observations early in the 20th century that had been digitized in the last decade or so. They also changed the spatial interpolation routines used to get areal averages and "adjusted" the station data to remove known biases or jumps from the reasons listed above.
The release of the new recomputed Climate Division Data set was well advertised among climate and weather circles and it was known that it would change some of the historical rankings. There is nothing too secret or nefarious going on here.
My own editorial....
I have always liked working with the raw station observations, in spite of all the flaws and warts. At least I know what these flaws are and how they impact the results.
NOAA NCDC has for years produced a data set called the U.S. Historical Climate Network (USHCN) where they choose a subset of stations with a long period of record and hopefully good siting and exposure, then "adjust" the observations to remove known biases and inconsistencies. Some of the known problems are instrument changes and observation practices (including time of observation), station moves, siting problems, and influences of urbanization around the station. They adjust the past observations to be more in line with recent and current observations at each station.
These adjustment methods sound good in theory and are all defensible from peer-reviewed literature, but the problem lies in that it is all done automatically with programmed algorithms that detect, then adjust for these biases and break points. It is the ultimate "black box", where no one outside of NCDC would be able to reproduce their processing. That alone is one opening for the seeds of distrust.
What is also bothersome is that the early decades of the station temperature records are consistently adjusted downward (cooler), so that now the century-long temperature trend is higher in the adjusted records than in the raw data.
The previous version of the NCDC Climate Division data set did not use the USHCN adjustment process on the historical station observations, but the new version does.
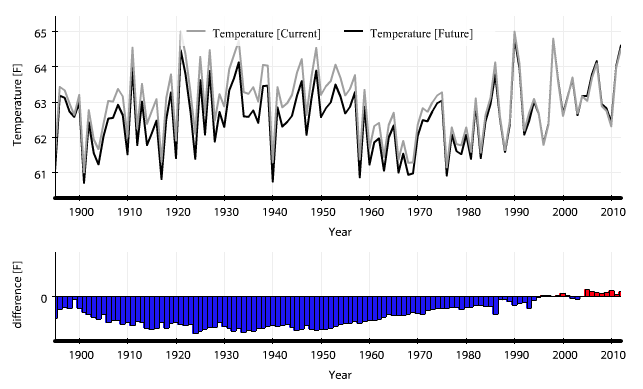
I have attached a graph of average annual temperature for the Southeast that compares the new Climate Division (black line) data with the older version (grey line). What we see is that the early part of the record has been adjusted downward (cooler) by over half a degree F! The adjustments are greatest from the 1930's through the 1950's, during what were known to be very hot decades in the Southeast and other regions.
Here is a link to NCDC's explanation of the transition:
http://www.ncdc.noaa.gov/monitoring-references/maps/us-climate-divisions.php
They also have a tool where you can compare the new and old data sets, but it does not seem to be working today?
http://www.ncdc.noaa.gov/temp-and-precip/divisional-comparison/
I am attending the annual meeting of the American Association of State Climatologist next week and representatives of NOAA's regional climate centers and NCDC will be there. I am sure this will be a hot topic!
| [ ] | 136 kB |